1 Introduction
You can usually get pretty far with SQL using simple queries like we’ve seen so far. You can get even further if you know how to use subqueries.
For this post I used the dataset flight from the statistics platform “Kaggle”. You can download it from my GitHub Repository.
2 Preparation
SET LANGUAGE ENGLISH
CREATE DATABASE Subqueries;
USE Subqueries;2.1 Loading the data set flight
How to load a dataset via SSMS into your database I described in this post: Read and write to files
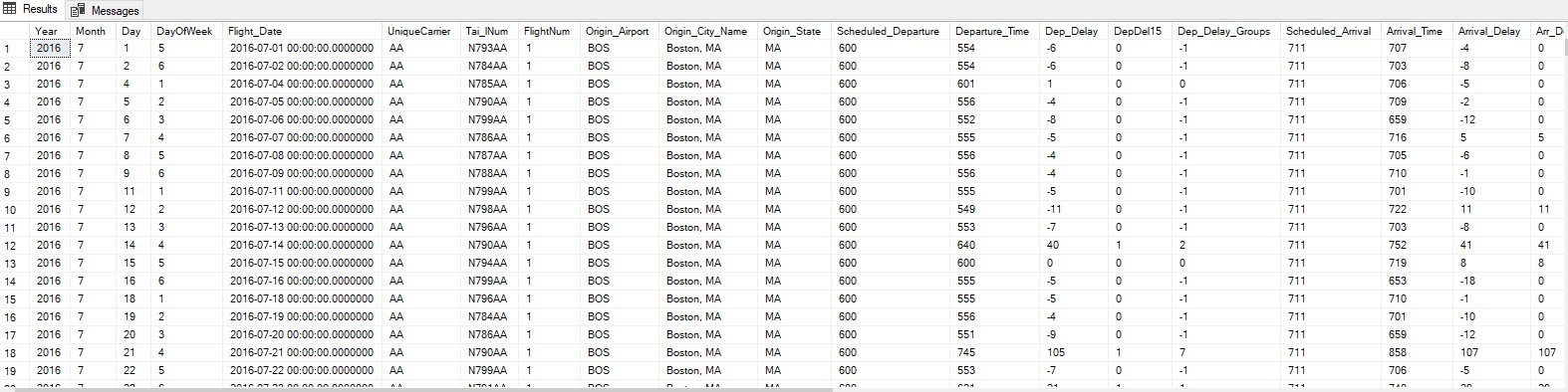
SELECT *
FROM flight
;
2.2 Creation of the flight_add_info dataset
Below we will still need the following dataset, which I will call flight_add_info.
CREATE TABLE flight_add_info
(Tai_lNum VARCHAR(100),
Manufacturer VARCHAR(100),
Typ VARCHAR(100),
Maximum_Speed INT,
Range INT)
;INSERT INTO flight_add_info (Tai_lNum, Manufacturer, Typ, Maximum_Speed, Range) VALUES ('N790AA', 'Airbus', 'A380', 1185, 15200)
INSERT INTO flight_add_info (Tai_lNum, Manufacturer, Typ, Maximum_Speed, Range) VALUES ('N787AA', 'Airbus', 'A340', 870, 10300)
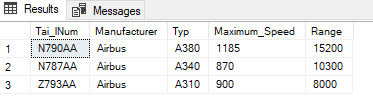
INSERT INTO flight_add_info (Tai_lNum, Manufacturer, Typ, Maximum_Speed, Range) VALUES ('Z793AA', 'Airbus', 'A310', 900, 8000)SELECT *
FROM flight_add_info
;
2.3 Creation of the customers dataset
And one more data set that we will need:
CREATE TABLE customers
(Name VARCHAR(100),
Age INT,
Salary INT)
;INSERT INTO customers (Name, Age, Salary) VALUES ('A', 25, 2000)
INSERT INTO customers (Name, Age, Salary) VALUES ('B', 33, 4000)
INSERT INTO customers (Name, Age, Salary) VALUES ('C', 23, 8500)
INSERT INTO customers (Name, Age, Salary) VALUES ('D', 27, 6000)
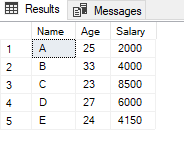
INSERT INTO customers (Name, Age, Salary) VALUES ('E', 24, 4150)SELECT *
FROM customers
;
3 Subqueries
Here is a short explanation of the difference between Subqueries and Joins:
Subquery: When an existing table needs to be manipulated or aggregated to then be joined to a larger table.
Joins: A fully flexible and discretionary use case where a user wants to bring two or more tables together and select and filter as needed.
3.1 Subqueries in the WHERE statement
For our first example, we will use the flight dataset.
There is a column there called ‘Dep_Delay’, which indicates the delay of aircraft departures. Let’s take a look at the mean value for this column:
SELECT AVG(Dep_Delay) AS avg_dep_delay
FROM flight
;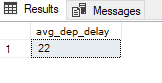
Now, if we want to look at which flights have a greater delay than this mean (22 minutes), we can write it like this:
SELECT Tai_lNum, Origin_Airport, Dep_Delay
FROM flight
WHERE Dep_Delay > 22
;
But it is not very smart, because the calculated mean value was hard coded here. There is another way to write this and that is with the help of Subqueries:
SELECT Tai_lNum, Origin_Airport, Dep_Delay
FROM flight
WHERE Dep_Delay > (SELECT AVG(Dep_Delay)
FROM flight)
;
Here we insert a subquery that calculates the mean value to which the main query can then reference.
3.2 Nested Subqueries in the WHERE statement
Of course, you can also use several subqueries nested within each other. Let’s take a look at the following data set:
SELECT *
FROM flight_add_info
;
What do I want to know here?
I want to display the additional information such as manufacturer or aircraft type (data set flight_add_info) for the aircraft whose delayed departure in the data set flight is above the mean.
So we use the above query including subquery only with the addition DISTINCT.
SELECT DISTINCT Tai_lNum
FROM flight
WHERE Dep_Delay > (SELECT AVG(Dep_Delay)
FROM flight)
;
Based on this, I now want to add all information for which Tai_lNum I also have further information available in flight_add_info.
SELECT *
FROM flight_add_info
WHERE Tai_lNum IN (SELECT DISTINCT Tai_lNum
FROM flight
WHERE Dep_Delay > (SELECT AVG(Dep_Delay)
FROM flight))
;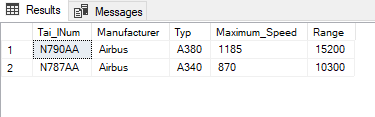
For two numbers I had additional information available. Of course, there are other flight numbers (‘Tai_lNum’) in the flight dataset that were above the mean in terms of departure delay, but for which I did not have any additional information (the dataset was of course very very small).
3.3 Subqueries in the FROM statement
So far we have written Subqueries in the WHERE statement. But this is also possible in the FROM statement.
Let’s have a look at this part of the flight dataset:
SELECT Flight_Date, Origin_Airport
FROM flight
;
First I extract the day from the date (‘Flight_Date’) and count the observations grouped by the day from the Flight_Date and the Origin_Airport.
SELECT DAY(Flight_Date) AS day,
Origin_Airport,
COUNT(*) AS event_count
FROM flight
GROUP BY DAY(Flight_Date), Origin_Airport
ORDER BY DAY(Flight_Date), Origin_Airport
;
The output what you see above is my base (and therefore my following Subquery) for my main query.
Tip: When I want to use Subqueries in a SQL statement, I always start writing with them.
SELECT Origin_Airport, AVG(event_count) AS avg_event_count
FROM (SELECT DAY(Flight_Date) AS day,
Origin_Airport,
COUNT(*) AS event_count
FROM flight
GROUP BY DAY(Flight_Date), Origin_Airport) AS sub
GROUP BY Origin_Airport
;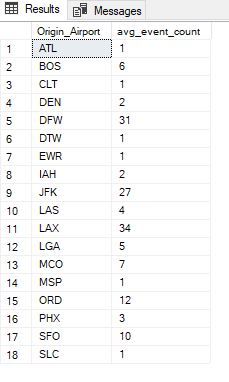
Based on the previously shown count (now integrated as a Subquery) I can now calculate the mean value of the counted observations grouped by Origin_Airport.
4 EXISTS Operator
The EXISTS Operator is used to test for the existence of any record in a Subquery.
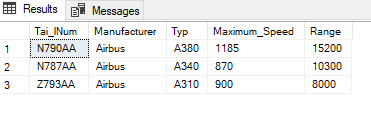
For example, if I want to check if the Tai_lNums in this table:
SELECT *
FROM flight_add_info
;
are also found in my large flight table (of course also within the column ‘Tai_lNum’), I can use the following command:
SELECT DISTINCT Tai_lNum
FROM flight
WHERE EXISTS (SELECT Tai_lNum
FROM flight_add_info
WHERE flight_add_info.Tai_lNum = flight.Tai_lNum)
;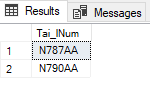
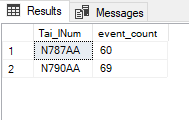
Fits perfectly. Two of the deposited numbers can also be found in flight. Now I display how often these numbers appear in flight:
SELECT Tai_lNum, COUNT(*) AS event_count
FROM flight
WHERE EXISTS (SELECT Tai_lNum
FROM flight_add_info
WHERE flight_add_info.Tai_lNum = flight.Tai_lNum)
GROUP BY Tai_lNum
;
This output can also be obtained by using the IN Clause:
SELECT DISTINCT Tai_lNum
FROM flight
WHERE Tai_lNum IN (SELECT DISTINCT Tai_lNum
FROM flight_add_info)
;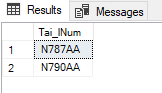
The IN is best used where you have a static list to pass like here.
Based on rule optimizer:
- EXISTS is much faster than IN, when the sub-query results is very large.
- IN is faster than EXISTS, when the sub-query results is very small.
EXISTS will be faster because once the engine has found a hit, it will quit looking as the condition has proved true.
With IN, it will collect all the results from the sub-query before further processing.
5 ANY and ALL Operator
Do I need more operators if I already have IN? Yes, because there is a very important difference between ANY/ALL and IN:
- With ANY or ALL you must place an =, <>, <, >, <=, or >= operator before ANY/ALL.
- But with the IN operator you cannot use =, <>, <, >, <=, or >=.
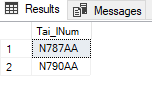
To get the last shown outputs (using EXISTS and IN) with ANY, I have to write the syntax as follows:
SELECT DISTINCT Tai_lNum
FROM flight
WHERE Tai_lNum = ANY (SELECT Tai_lNum
FROM flight_add_info
WHERE flight_add_info.Tai_lNum = flight.Tai_lNum)
;
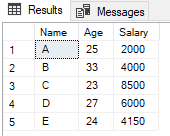
To understand ANY and ALL even better, let’s consider the following example (dataset customers):
SELECT *
FROM customers
;
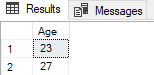
Let’s take a look at the people (we only let the age of the people output) whose income is greater than 5,000.
SELECT Age
FROM customers
WHERE Salary > 5000
;
Now we use ANY once and ALL once in the WHERE statement:
SELECT *
FROM customers
WHERE Age > ANY(SELECT Age
FROM customers
WHERE Salary > 5000)
;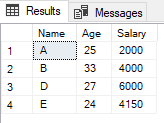
All persons whose age is greater than 23 or 27 are output here.
Now with ALL:
SELECT *
FROM customers
WHERE Age > ALL(SELECT Age
FROM customers
WHERE Salary > 5000)
;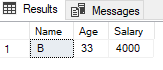
Only persons whose age is greater than 27 are output here.
Here again IN, ANY and ALL in a nutshell:
- IN: Equals to Anything in the List
- ANY: Compares Value to Each Value Returned by the Sub Query
- ALL: Compares Value To Every Value Returned by the Sub Query
6 Conclusion
In this post I have shown how to create subqueries and use them with
- EXISTS
- IN
- ANY and
- ALL