1 Introduction
After I have already reported on how to set up databases, we now come to a very important topic that is related to this: What should I consider when setting up the data structure?
So in this post, I want to cover Database Normalization.
2 Theoretical Background
2.1 What is Normalization in a Database?
Normalization is the process of reducing redundancy of data in the table and also improving data integrity. Normalization split a large table into smaller tables and define relationships between them to increases the clarity in organizing data.
2.2 Problems without Normalization
Normalization is necessary because without normalization in SQL many problems can occur. These can be, for example:
- Insertion Anomaly: It occurs when we cannot insert data into the table without another attribute being present.
- Update Anomaly: It is a data inconsistency that occurs due to data redundancy and partial update of data.
- Deletion Anomaly: It occurs when certain attributes are lost due to deletion of other attributes.
2.3 Rules for Data Normalization
There are three main forms for Data Normalization:
- First Normal Form (1st NF)
- Second Normal Form (2nd NF)
- and Third Normal Form (3rd NF)
Normalization was developed by IBM researcher E.F. Codd in the 1970s. In doing so, he established some rules for satisfying the normal forms.
First Normal Form (1st NF)
- Same Data Type in a Column.
- There are only Single Valued Attributes.
- There is a Unique name for every Attribute/Column.
- Uniquely identify a Row.
Second Normal Form (2nd NF)
- Be in 1st NF.
- The table should also not contain Partial Dependencies.
Third Normal Form (3rd NF)
- Be in 2nd NF.
- The table should also not contain Transitive Dependencies.
3 Database Normalisation
In the following I will give examples that show how to bring unnormalized data into the next Normal Form.
3.1 First Normal Form (1st NF)
3.1.1 Same Data Type in a Column
In order to work with data within a column in a meaningful way, it is mandatory that these data correspond to the same data type.
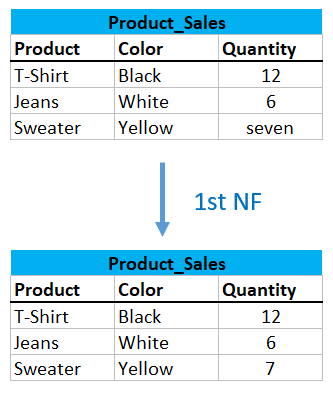
3.1.2 There are only Single Valued Attributes
Likewise, unnecessary duplicate columns must be avoided.
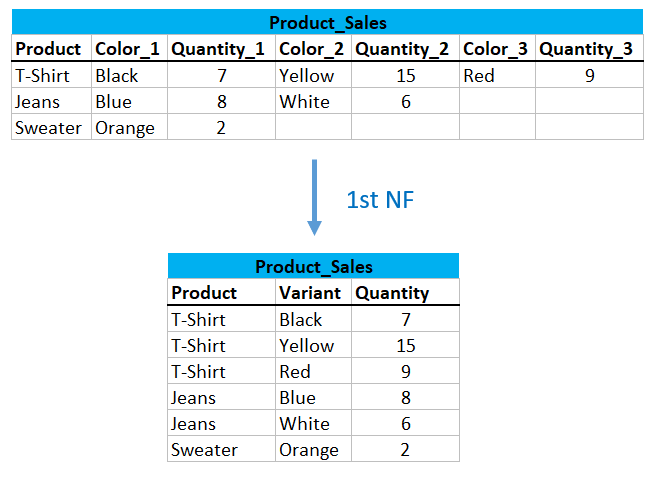
3.1.3 There is a Unique name for every Attribute/Column
All information in an observation should be available for query. If several values are stored within one cell, this could cause problems.
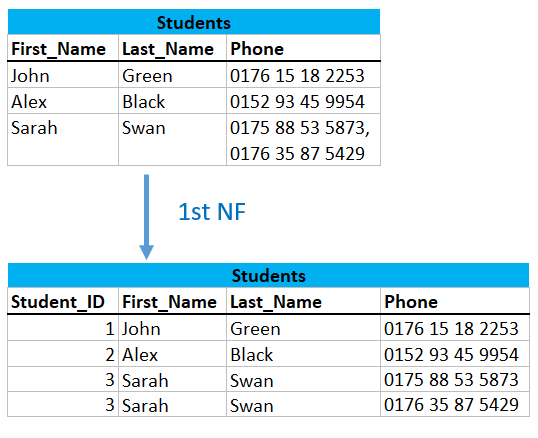
3.1.4 Uniquely identify a Row
Individual Observations must be identifiable. A good solution to the problem at hand would be to split the source table.
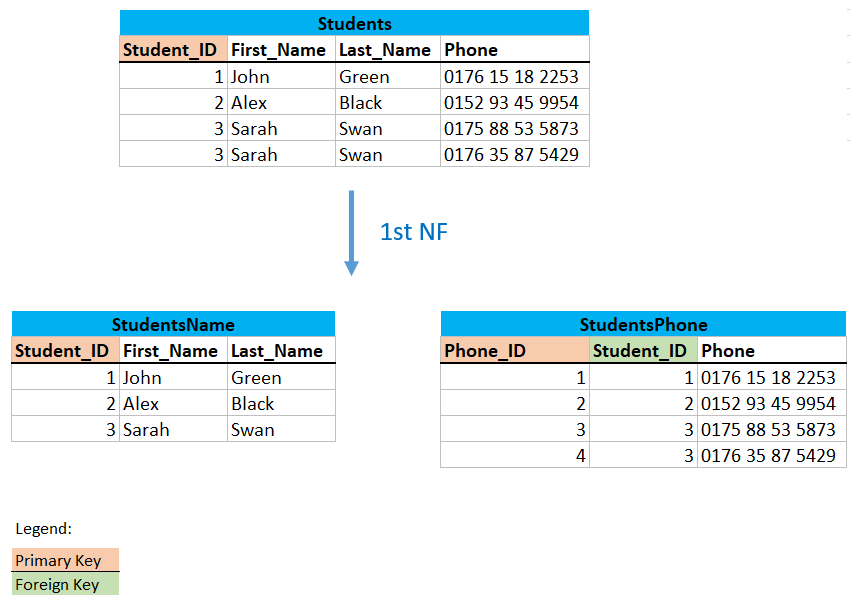
3.1.5 Digression: Primary Key vs. Foreign Key
In the previous example we saw the use of primary keys and a foreign key. But what are these keys actually and what do I need them for?
A primary key is used to ensure that the data in a particular column is unique. The primary key must not contain NULL values or repeating values, is limited to a single table, and is set to uniquely identify the corresponding rows of a table. This is either an existing table column or a column that is specially generated by the database according to a defined sequence.
A foreign key is a column or a group of columns in a relational database table that refers to the primary key of the other table. It is responsible for managing the relationship between the tables. The table that contains the foreign key is usually called the child table. The table whose primary key is referenced by the foreign key is usually called the parent table.
The use of Primary Keys and Foreign Keys also have a protective function. For example, in the example above, if we want to add another phone number to the StudentsPhone table and I make a mistake with the Student_ID (for example, if I want to use one that doesn’t exist at all), I would get an insert error saying that this primary doesn’t exist at all in the parent table.
3.2 Second Normal Form (2nd NF)
Now that we know what the first normal form must look like, we come to the second normal form.
Let’s take a look at this sample table (‘Sales_Table’):
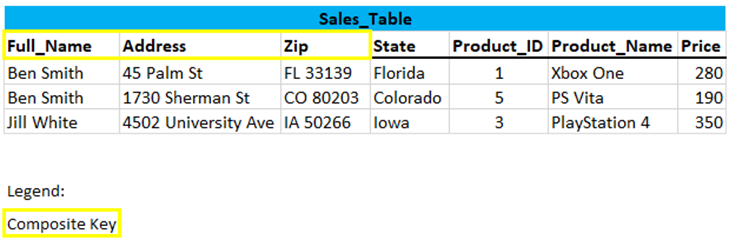
3.2.1 Digression: Composite Key
Is this table really in the first normal form? I don’t see any primary key here at all… The answer is: yes it is. We do not have a primary key here, but a composite key.
What is a composite key?
A composite key is a primary key composed of multiple columns used to identify a record uniquely. This table has a composite primary key Full_Name, Address and Zip.
With these three specifications, the lines can be clearly distinguished from each other, thus the first normal form is achieved.
3.2.2 Add a Primary Key
Of course, it is better to work with primary keys. So in a first step I add this one.
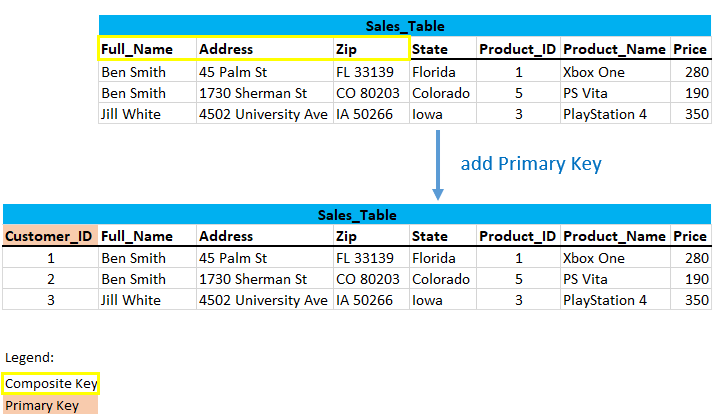
3.2.3 Digression: Candidate Key
So far so good. Let’s take a closer look at the modified table and see what structure we have here:
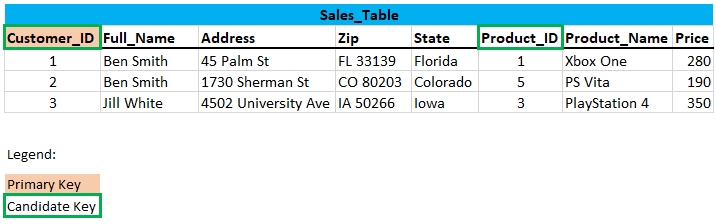
If we look at the Customer_ID and Product_ID columns we see that these are two candidate keys.
What is a candidate key?
A candidate key is a set of attributes (or attribute) which uniquely identify the tuples in relation or table. Candidate key’s attributes can contain a NULL value which opposes to the primary key.
3.2.4 Split the Table
In preparation to bring this table into the second normal form, we should divide the table at this point to continue. This may look like the following:
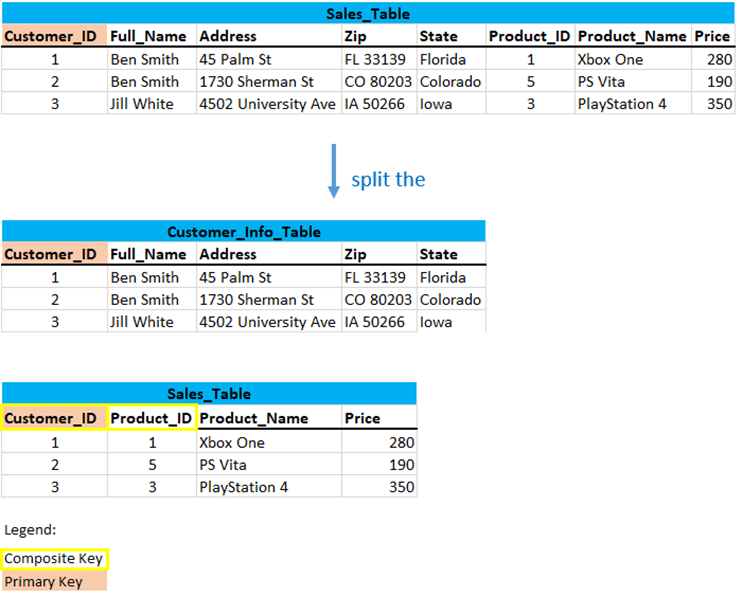
3.2.5 Partial Dependencies
As we know from the rules for normalizing data the table should not contain partial dependencies. Partial dependency means that a non-key attribute is functionally dependent on part of a composite key.
Let’s take a closer look at the Sales table that was created:
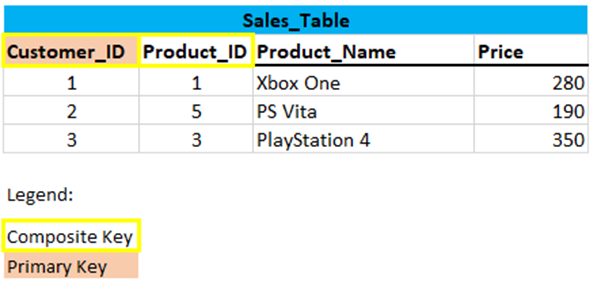
Customer_ID and Product_ID again result in a composite primary key. The non-key attributes are Product_Name and Price.
In this case, Product_Name and Price only depends on Product_ID, which is only part of the primary key. Therefore, this table does not satisfy the second Normal Form.
To bring this table to Second Normal Form, we need to break the table into two parts again.
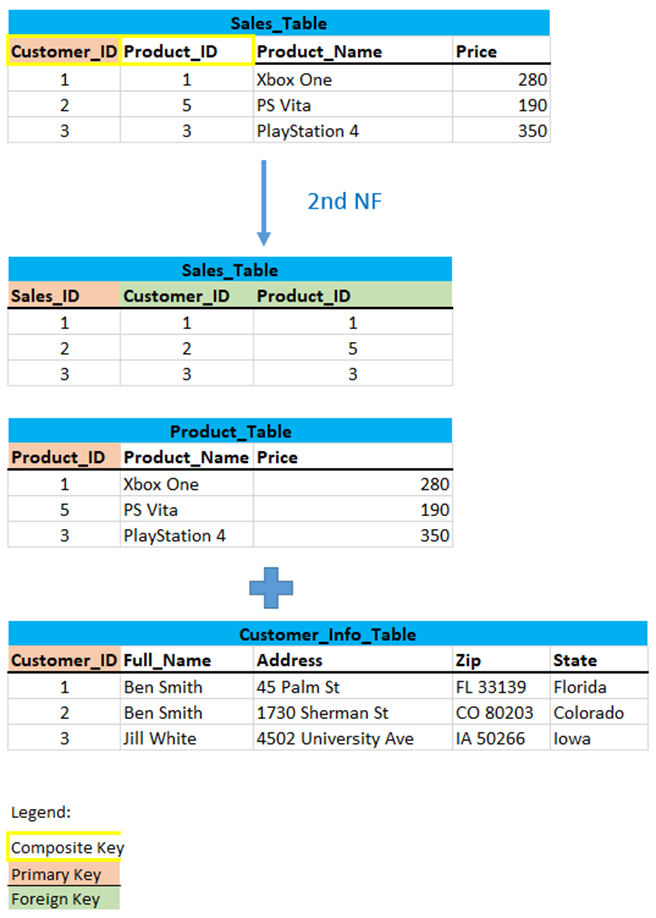
Now there is no partial dependency anymore. For a complete view, I have included the Customer_Info_Table in the previously shown diagram.
3.3 Third Normal Form (3rd NF)
Our two tables Sales_Table and Product_Table are now in the targeted normal form. Remains only the study of the remaining Customer_Info table.
3.3.1 Transitive Dependencies
The rule for achieving the third normal form states that the table should also not contain transitive dependencies.
Transitive dependency is nothing but, a non-prime attribute (other than candidate key) depending on another non-prime attribute which is entirely dependent on candidate key.
3.3.2 Remove Transitive Dependencies
Let’s take a look at the Customer_Info table:
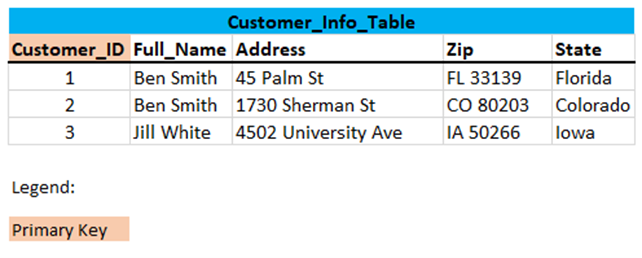
Address -> Full_Name: Here, the Address attribute determines the Full_Name attribute. If you know the exact address, you can get the customers name. However, the customers name does not determine the address, because a customer can have multiple addresses.
Address -> Zip: Likewise, the Address attribute determines the Zip, but not the other way around, just because we know the Zip does not mean we can determine the Address.
But this table introduces a transitive dependency:
Zip - > State: If we know the Zip, we can determine the State via the Address column.
To ensure 3rd NF, let’s remove the transitive dependency. We can start by removing the State column from the Customer_Info table and creating a separate State table:
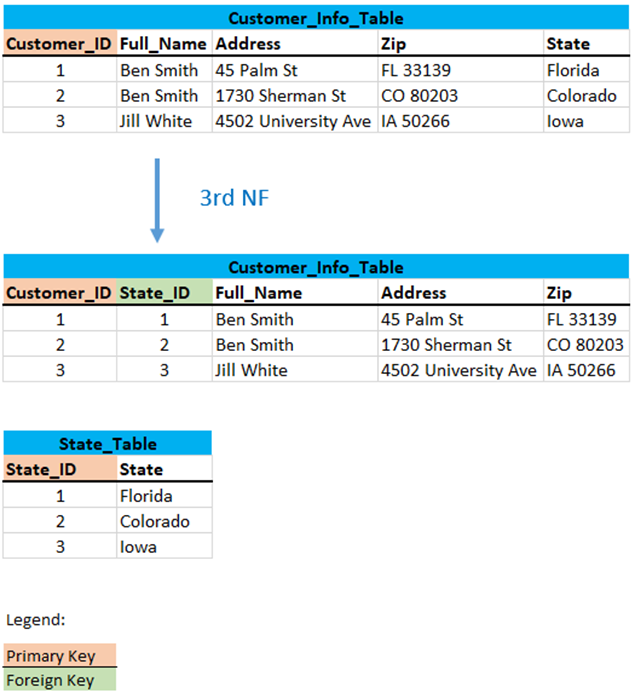
3.3.3 Why Transitive Dependencies Are Bad Database Design
For this section we can look again at the origin table:
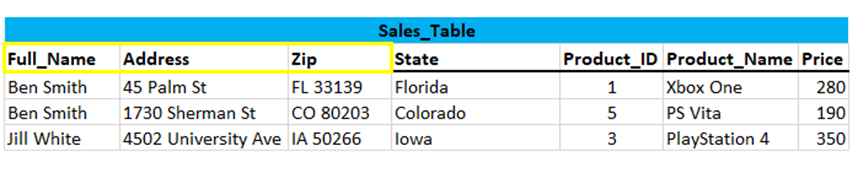
If you delete the two customers ‘Ben Smith’ from Miami and ‘Jill White’, we would also lose all the information we have enriched on East America in this dataset (if we had done that).
You cannot add a new address to the database without adding a name as well. What would happen if you were provided with a free set of locations? You would not be able to use it until you have a customer that matches one of these addresses.
If one of the customers changes their address (for example, due to a change of residence), you would need to go through all of that customer’s orders and change the Address column. Having multiple records with the same customer can lead to inaccurate data. What if the person entering the data doesn’t realize there are multiple records for him and changes the data in only one record?
The benefits of removing transitive dependencies are:
- Amount of data duplication is reduced.
- Data integrity achieved.
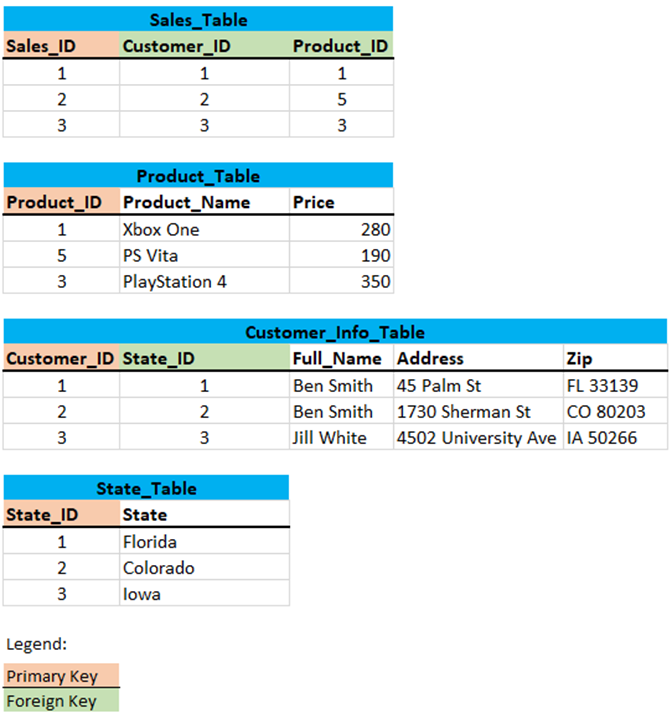
3.3.4 Final tables (in the third normal form)
Here again a short overview of all created tables in the third normal form:
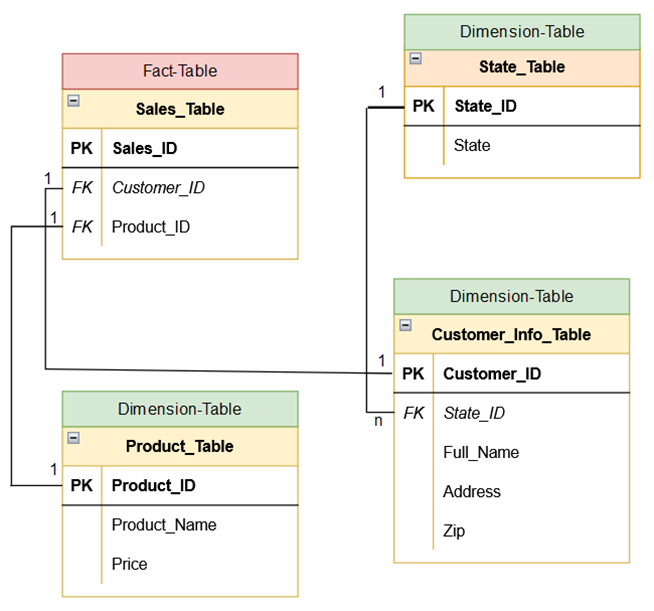
And here is the view with the associated cardinality (Chen-Notation):
4 Conclusion
In this post I have explained what normalization of a database means and what rules exist for it. For all the rules I have listed examples that you can use to understand the meaning of the rules.